Machine Learning Dataset Tour (3): Loan Prediction
TL;DR: you can view my work on my GitHub.
In this post, I am going to make a brief introduction of loan prediction dataset, and I will share my solution with some explanation.
Brief Introduction of Loan Prediction Dataset
Provided by Analytics Vidhya, the loan prediction task is to dicide whether we should approve the loan request according to their status. Each record contains the following variables with description:
| Variable | Description |
|---|---|
| Loan_ID | Unique Loan ID |
| Gender | Male/Female |
| Married | Applicant married (Y/N) |
| Dependents | Number of dependents |
| Education | Applicant Education (Graduate/ Under Graduate) |
| Self_Employed | Self employed (Y/N) |
| ApplicantIncome | Applicant income |
| CoapplicantIncome | Coapplicant income |
| LoanAmount | Loan amount in thousands |
| Loan_Amount_Term | Term of loan in months |
| Credit_History | credit history meets guidelines |
| Property_Area | Urban/ Semi Urban/ Rural |
| Loan_Status | Loan approved (Y/N) |
For more details, you can visit the official post.
Goal and Evaluation Metric
Goal
- The goal is to approve/decline a person’s loan by given condition.
Evaluation Metric
- accuracy
- percentage of loan approval you correctly predict.
My Solution
- As the data is provided in tabular from, I will choose decision tree based model.
- In this post, I choose random forest.
- Because some of the features have null value, I will use either drop the records with null values or fill a value instead.
- I eventually choose to fill the missing feature value which appears the most often in each feature because to few training data.
- Since the testing data does not provide ground truth, the model will be trained with cross validation of training data.
Step-by-step Explaination
1. Prepare Data and Make Some Explorations
Using pandas’ info() method, I find some features’ type is object:
- Loan
- Gender
- Married
- Dependents
- Education
- Self_Employed
- Property_Area
- Loan_Status
Using pandas’ isnull() method, I find some features contain null value:
- Gender
- Married
- Dependents
- Self_Employed
- LoanAmount
- Loan_Amount_Term
- Credit_History
I then use seaborn to check the distribution of each variable between Loan_Status = ‘Y’ v.s. ‘N’:
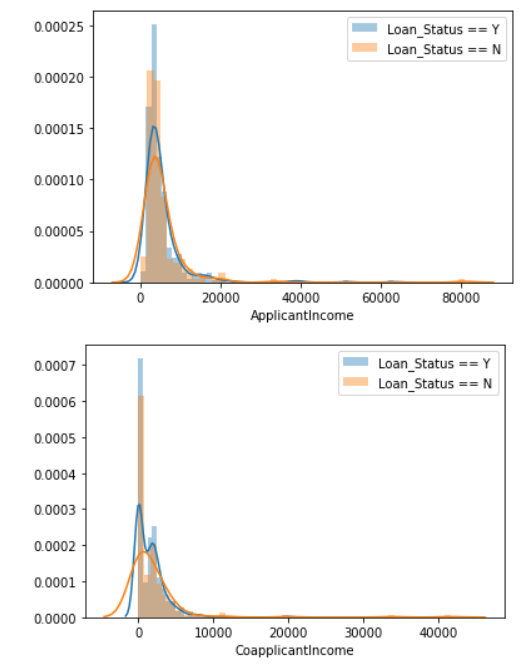
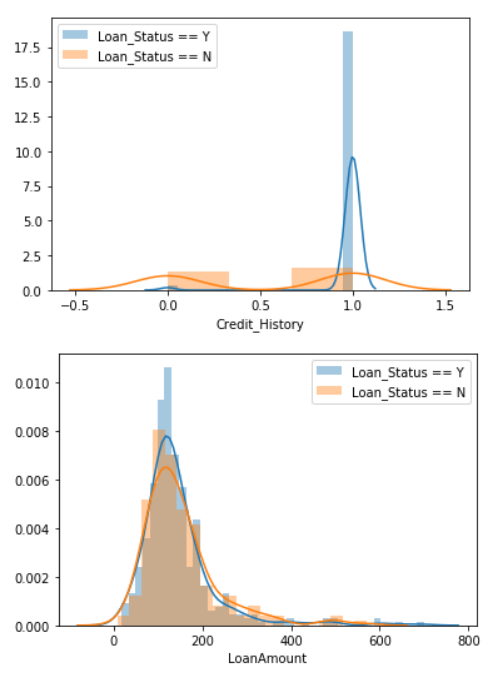
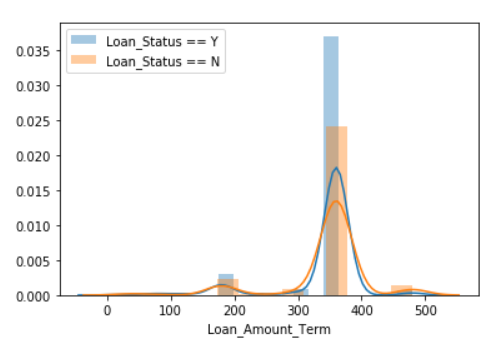
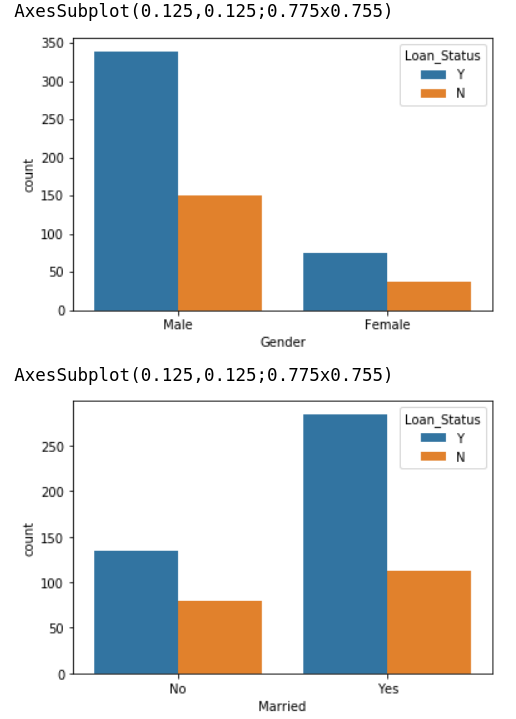
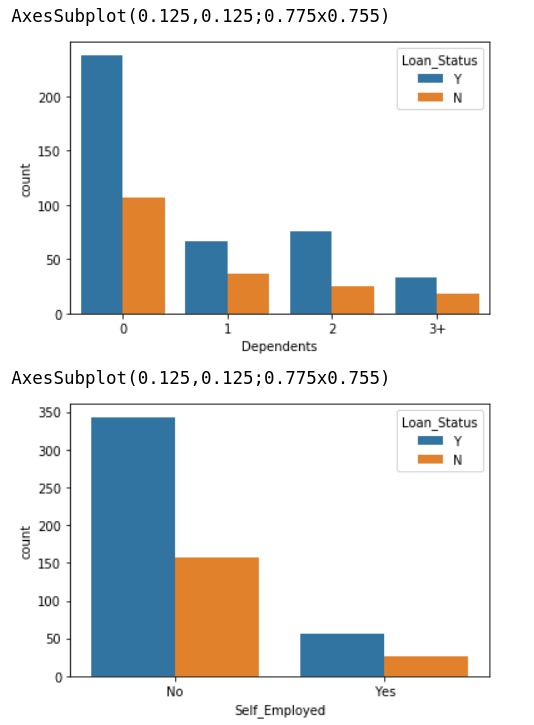
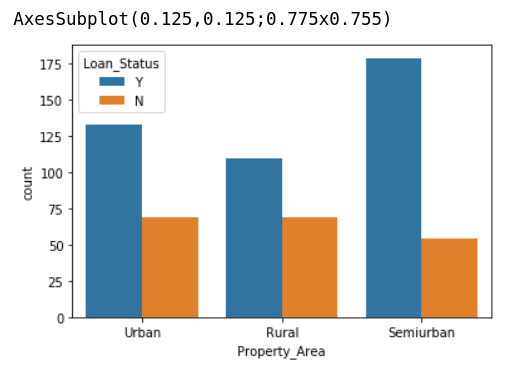
In summary, I make some outlines:
- Loan_ID is not relevent (it should not be treated as a feature because it just the ID of each record).
- Loan_Status should not be treated as a feature because it is the target.
- The higher Y/N ratio, the more possible to get the loan to be approved.
2. Feature Engineering
The feature engineering methods I use in this mission includes:
- Fill the missing values with
mode()
Thanks to the few training data, I fill the missing value withmode()method in pandas. Themode()method will return the value appear the most often [1]. - One-hot encoding to categorical features
Mentioned in previous part, some of the features are categorical type, so I use one-hot encoding to indicate which class the feature belongs to. - Label encoding to target value
I think applyig one-hot encoding is not suitable to represent target value. Therefore, I adopt label encoding to represent the class of target value.
3. Prepare Baseline Model
After feature engineering, I prepare the default random forest classifier to predict whether a person will
get his loan approval in accordance with his situation.
Also, I apply cross validation to evaluate the score, and the accuracy of this baseline model is 75%.
Hmm, pretty plain. Let’s try we can improve it by tuning its hyperparameters.
4. Hyperparameter Searching with Random Search
To find the best hyperparameters of a model, we can use the following two methods:
- random search
- grid search
Random search tries the combination of hyperparameters randomly, while grid search tries the combination of
hyperparameters one by one. In general, grid search produces the better result but takes much more time to
try the combination. As a result, I will use random search to find the best combination in a short time.
Of course, I adopt RandomizedSearchCV because I am using sklearn’s random forest classifier.
After running random search, we can get the best hyperparameters by using best_params_ object:
{'n_estimators': 546,
'min_samples_split': 2,
'min_samples_leaf': 4,
'max_features': 'sqrt',
'max_depth': 10,
'bootstrap': True}
I then use these params to create a random forest classifier mentioned in the next part.
5. Train and Evaluate the Model
After we get the params, we can create the model which should performs better than the baseline model. I also
use cross validation to evaluate the model.
The accuracy of this model is 81%, which gains more 6% accuracy than baseline model. Sounds great.
Conclusion
In this post, I briefly introduce the Loan Prediction Dataset, and I show step-by-step operation to show my
solution. What’s more, I demonstrate we can further improve the performance of model up to 6% by using random
parameter search to get the best hyperparameters.
See you in the next tour, bye!
You can view my work on my GitHub.
Reference
[1] https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.mode.html